Android / llama.cpp / GGUF
LLM AI Server with llama.cpp
LLM AI Server with llama.cpp は、Android 端末上で GGUF モデルを読み込み、推論設定・プロンプトテンプレート・共有 MCP / Function Definitions 設定・ログ確認・Ollama/OpenAI 互換 API と同梱 WebUI の公開までを一つのアプリで扱えるローカル LLM 検証ツールです。
文書: 操作マニュアル | API リファレンス | 技術仕様 | llama.cpp / JNI / CMake 深掘り | プライバシーポリシー
- モデル URL からのダウンロードと、端末内
.ggufファイルの取り込みに対応します。 - 生成パラメータ、Think 設定、カスタム chat template、共有 MCP 設定、Function Definitions JSON を組み合わせて運用できます。
- 必要に応じて端末内で Ollama/OpenAI 互換 API と WebUI を同じポートで起動し、
/api/chatや/v1/chat/completionsを利用できます。
スクリーンショット
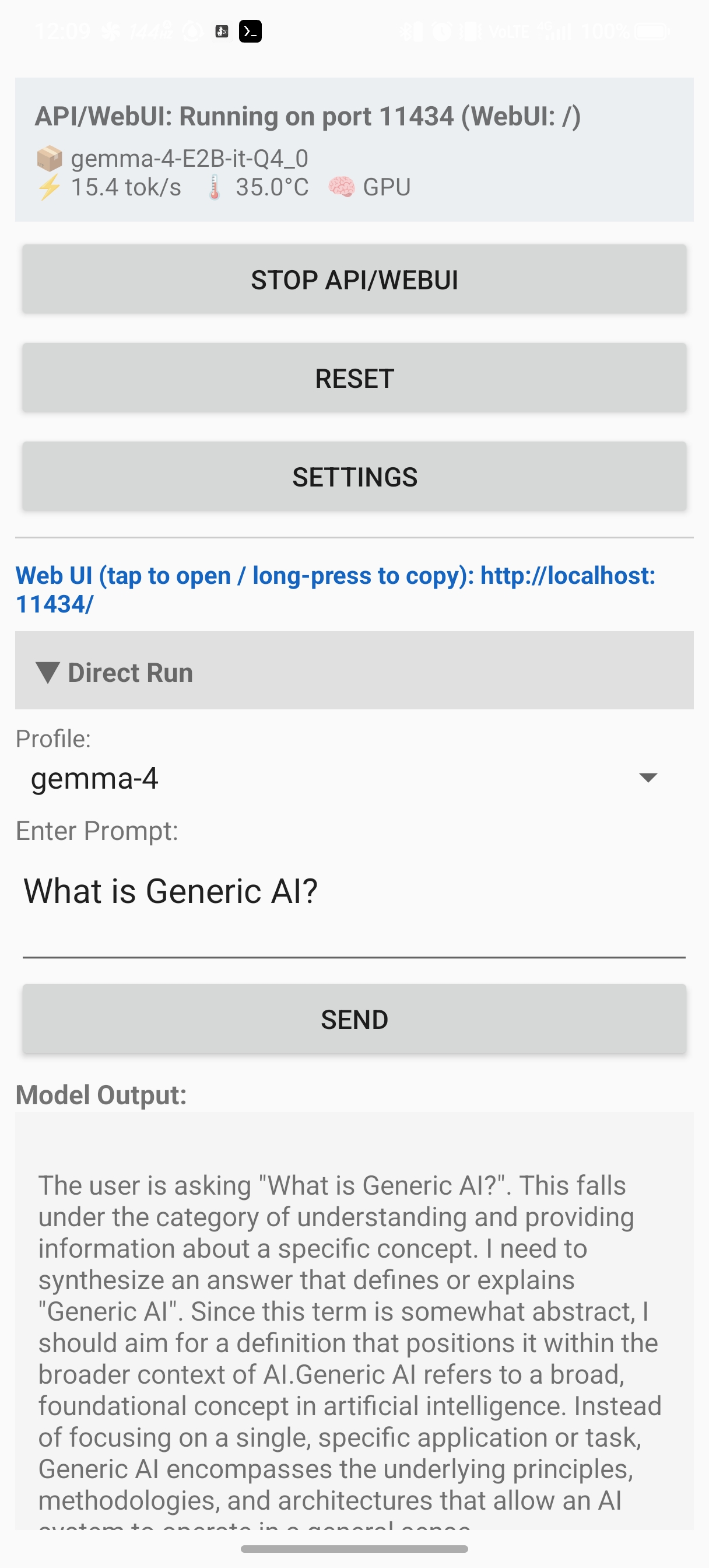
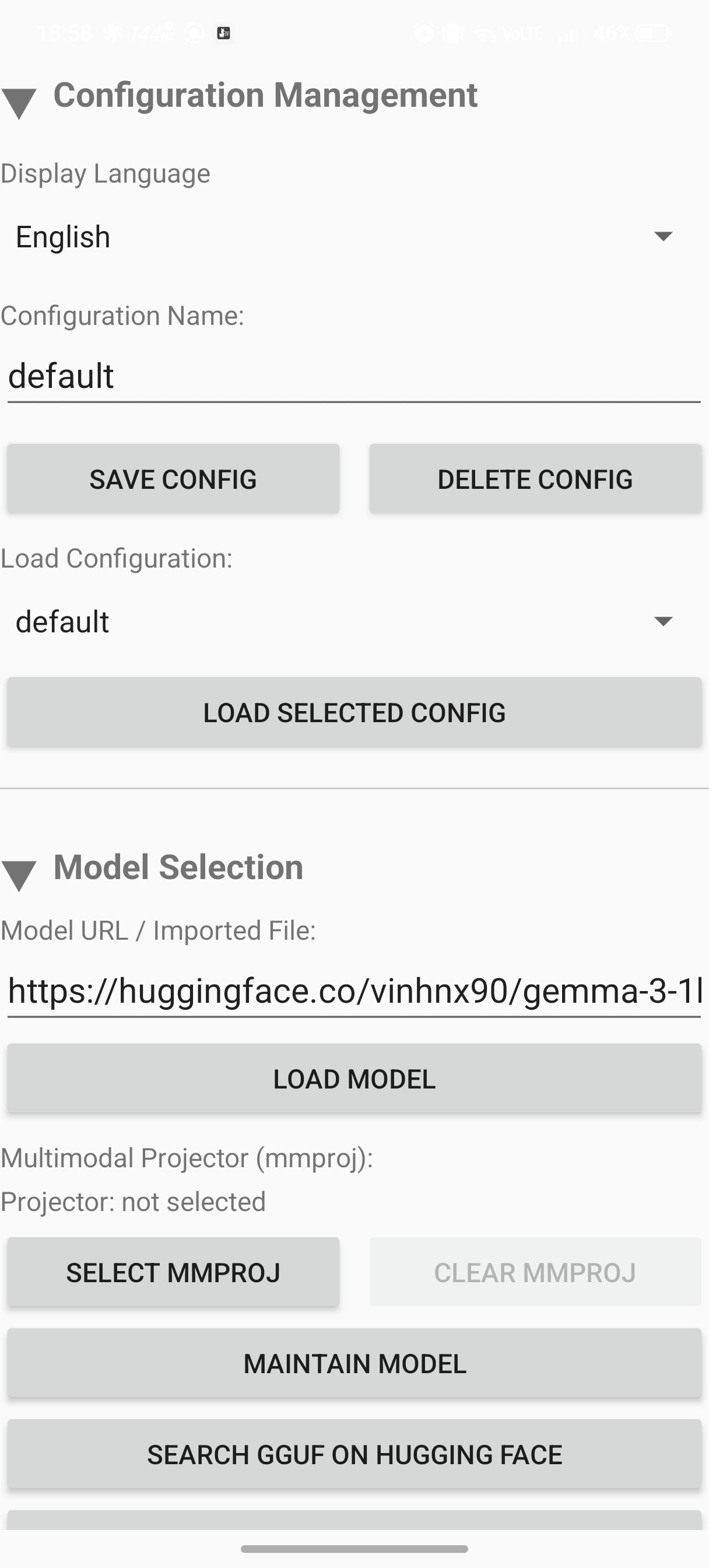

主な特徴
- 端末内でのローカル推論: llama.cpp を使って Android 端末上で GGUF モデルを直接実行します。
- モデル導入の自由度: HTTP/HTTPS のモデル URL 指定と、ローカル端末からの
.gguf取り込みの両方に対応しています。 - 詳細な推論制御:
n_ctx、n_threads、コンピュートバックエンド(CPU / GPU)、オフロード層数、Top-p、Top-k、Penalty、Mirostat、DRY、Think、custom chat template まで調整できます。 - MTP 投機デコード(実験的): MTP ヘッドを内蔵するモデル(Qwen3.5-MTP, Gemma 4 など)で MTP(投機デコード, draft-mtp)をモデル別プロファイルで有効化できます。既定 OFF、
n_draft調整可、追加ファイル不要(自ヘッド使用)。対応環境では生成が高速化する場合があります。 - 共有 MCP / Function Calling 設定: モデル別プロファイルとは別に MCP Config JSON と Function Definitions JSON を保存でき、外部利用スイッチを有効にするとメイン画面、
/api/chat、/api/generate、/v1/chat/completionsでも共通利用されます。 - 内蔵 Ollama/OpenAI 互換 API と WebUI:
/api/chat、/api/generate、/api/tags、/v1/chat/completions、/v1/models、/props、/slotsを同じポートで提供し、同時生成は 1 件、待機キューは最大 10 件・最大 60 秒です。 - マルチモーダル API 入力:
/api/chatと/v1/chat/completionsではimage_urlとinput_audioを扱え、ロード済みモデルの vision/audio 対応状況に応じて利用できます。
運用メモ
- 大きなモデルの取得には数 GB 単位の通信が必要になる場合があります。モデルのダウンロードは Wi-Fi 環境が推奨です。
- ローカル API サーバーは同一端末またはローカルネットワーク向けの利用を想定しています。Android 13 以降では通知権限が必要になる場合があります。
- MCP サーバーを設定してメイン画面、API、または WebUI から利用する場合、会話内容やツール入力の一部が設定先 MCP サーバーへ送信されることがあります。